C2: Collaborative Conversation — Building a Long-term Group Collaboration Dataset
Motivation
Real collaboration is multi-party and long-term; yet most AI interaction data and models target dyadic, short sessions. We aim to build a large-scale, authentic dataset to study emergent roles, collaboration quality, and long-horizon memory in team settings.
Contribution
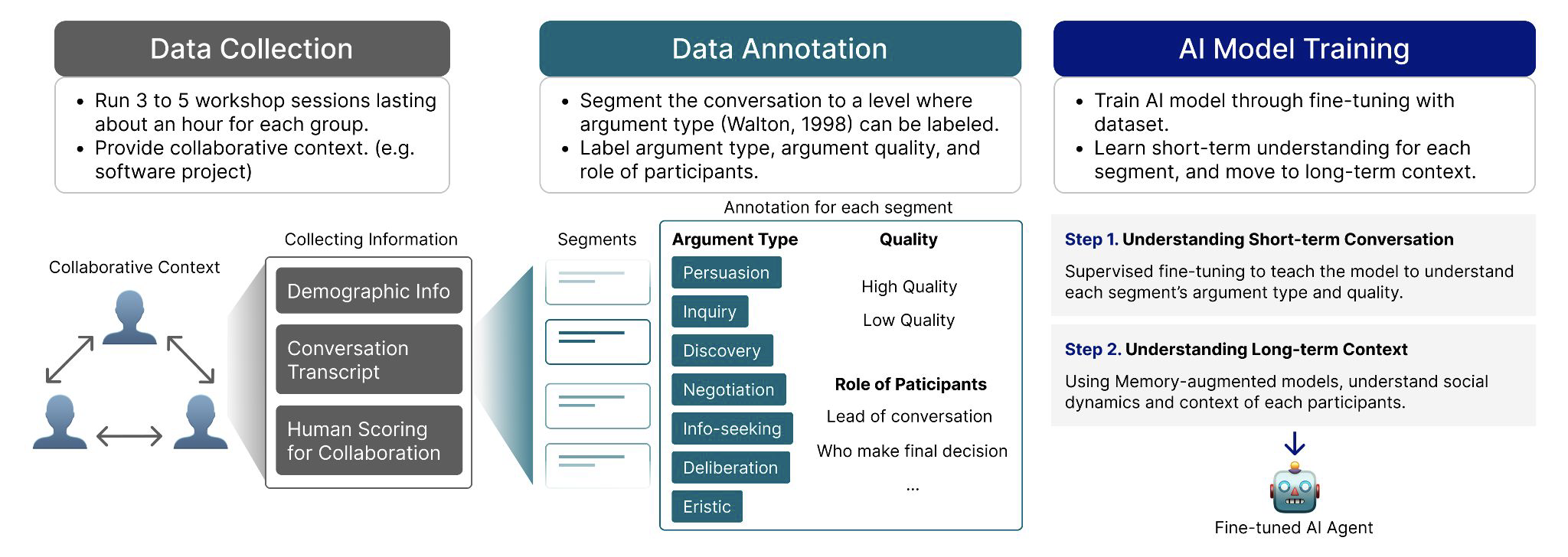
- Curate long-term, multi-party collaboration data (audio → transcripts), linked with daily surveys and development artifacts.
- Design a compact schema capturing roles, arguments, and utterances; apply a semi-automated LLM labeling pipeline seeded by a golden set.
- Deliver pilot data and analysis to inform role-aware, socially capable AI agents.
Methods & Experiments
We explored diarization + ASR, segmentation into utterances/arguments, anonymization, and LLM-assisted labeling. A pilot with one student team (~80 hours over 15 workdays) validated feasibility. Next, we plan multi-team collection during the fall semester to scale coverage and evaluate robustness.